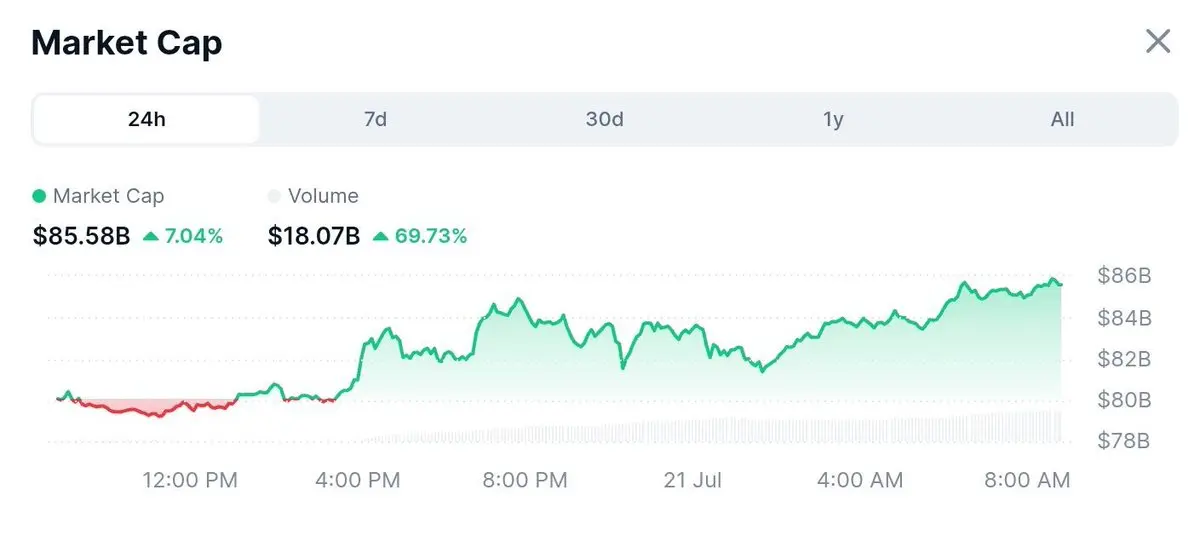
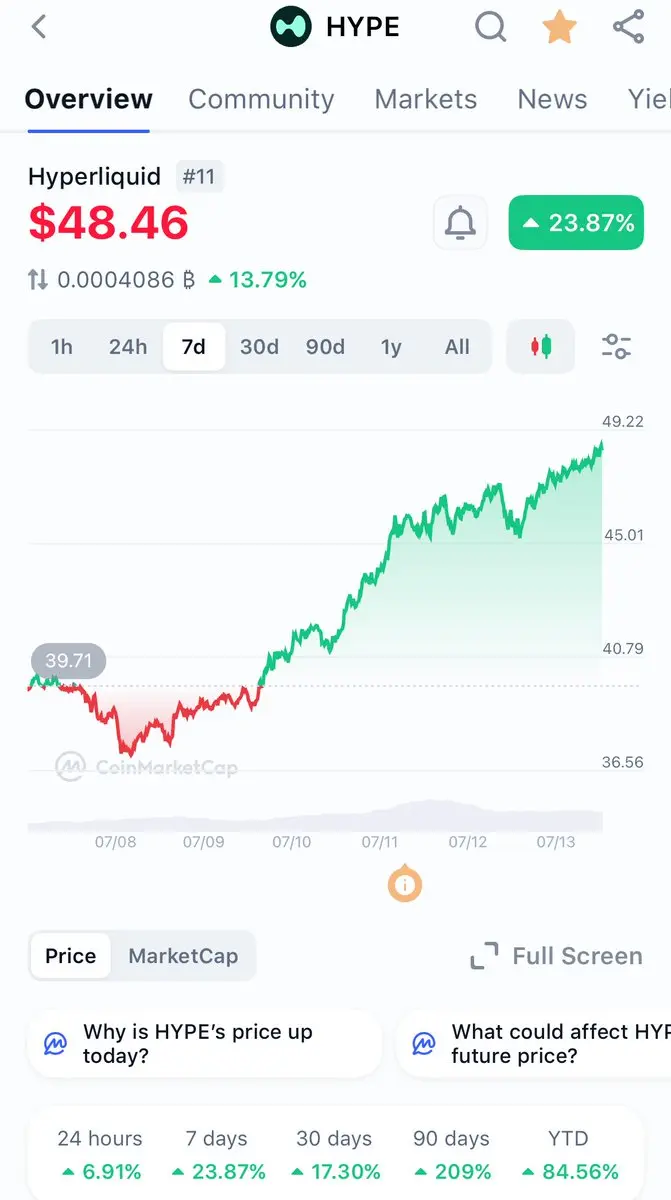
Kingbest
今天的默认AI拥有更大的基础模型,但它们速度慢、成本高且难以专业化。
而从中来看,你无法用一个1000万美元的巨头来提升智能。
你通过模块化来扩展它。
以太坊并没有变得更快。它通过将状态拆分为模块化的方式:
-rollups
- 分片
- DA 图层
@Mira_Network 将相同的原则应用于 AI,通过 LoRA
LoRA = 智能碎片
每个LoRA都是一个小型、专业化的模块;一个专业知识的片段。
- 一种用于DeFi白皮书的LoRA
- 一个用于DAO提案
- 用于多语言摘要
你不需要通才。
您组成了专家。
它是如何运作的
1. ModelFactory: 任何人都可以训练 LoRA 模块
2. OpenLoRA 注册表:每个 LoRA 都是链上、可组合和可追溯的
3. 模型路由器:将查询路由到正确的LoRA群
4. Mira 节点:通过多模型共识验证输出
这就像以太坊的分片用于认知一样。
为什么这种方法胜出
- 比重新训练完整模型便宜
- 更快的专业化
- 开放的去中心化AI创作
没有中央控制。没有黑箱。
仅仅是模块化智能;可验证、高效,并且为规模而构建。
查看原文而从中来看,你无法用一个1000万美元的巨头来提升智能。
你通过模块化来扩展它。
以太坊并没有变得更快。它通过将状态拆分为模块化的方式:
-rollups
- 分片
- DA 图层
@Mira_Network 将相同的原则应用于 AI,通过 LoRA
LoRA = 智能碎片
每个LoRA都是一个小型、专业化的模块;一个专业知识的片段。
- 一种用于DeFi白皮书的LoRA
- 一个用于DAO提案
- 用于多语言摘要
你不需要通才。
您组成了专家。
它是如何运作的
1. ModelFactory: 任何人都可以训练 LoRA 模块
2. OpenLoRA 注册表:每个 LoRA 都是链上、可组合和可追溯的
3. 模型路由器:将查询路由到正确的LoRA群
4. Mira 节点:通过多模型共识验证输出
这就像以太坊的分片用于认知一样。
为什么这种方法胜出
- 比重新训练完整模型便宜
- 更快的专业化
- 开放的去中心化AI创作
没有中央控制。没有黑箱。
仅仅是模块化智能;可验证、高效,并且为规模而构建。